
Fig1. 3D rendered accurate illustration of the hippocampus.
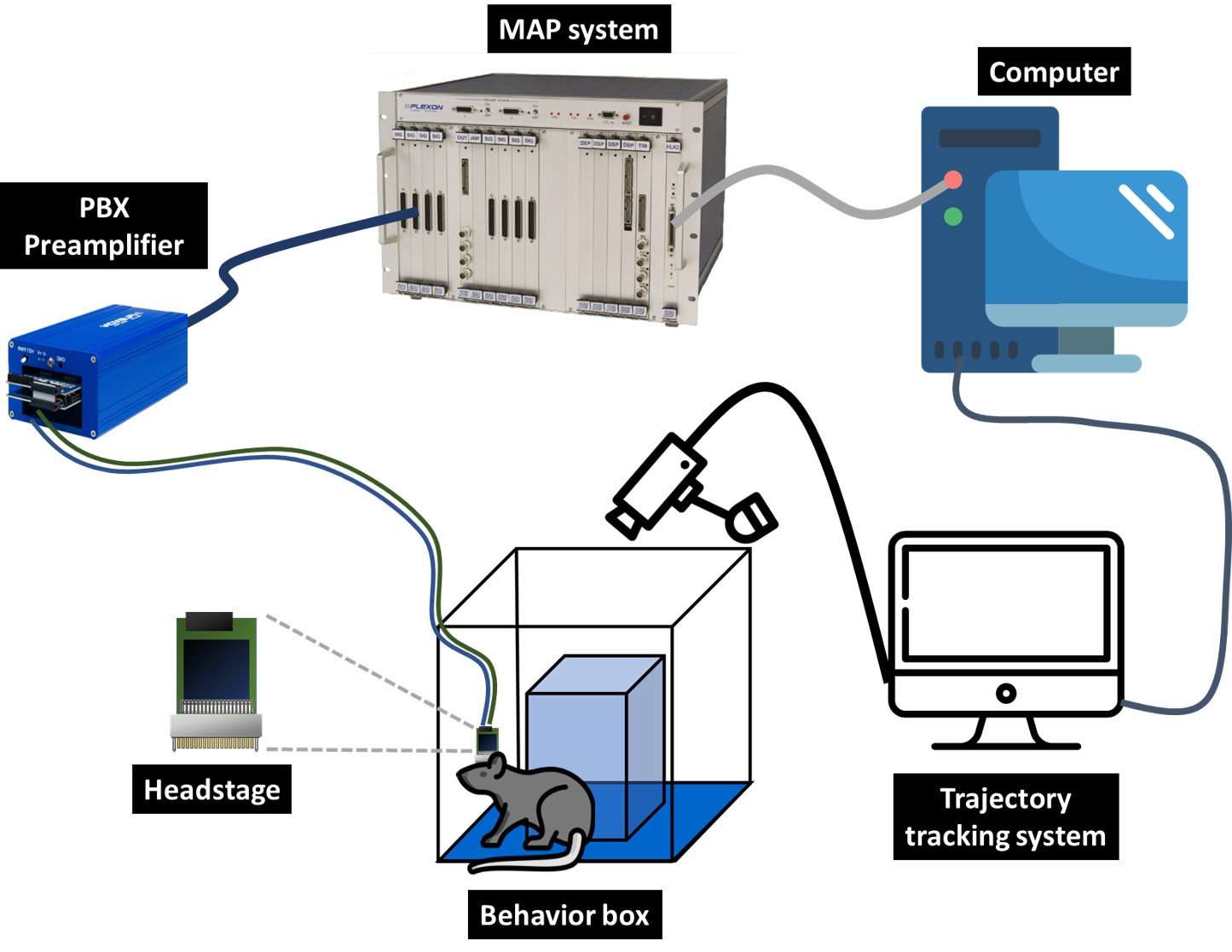
Fig2. The architecture of the electrophysiological neuron recording system and the animal trajectory recording system with the setting of the experimental environment for water reward-related lever-pressing learning task.
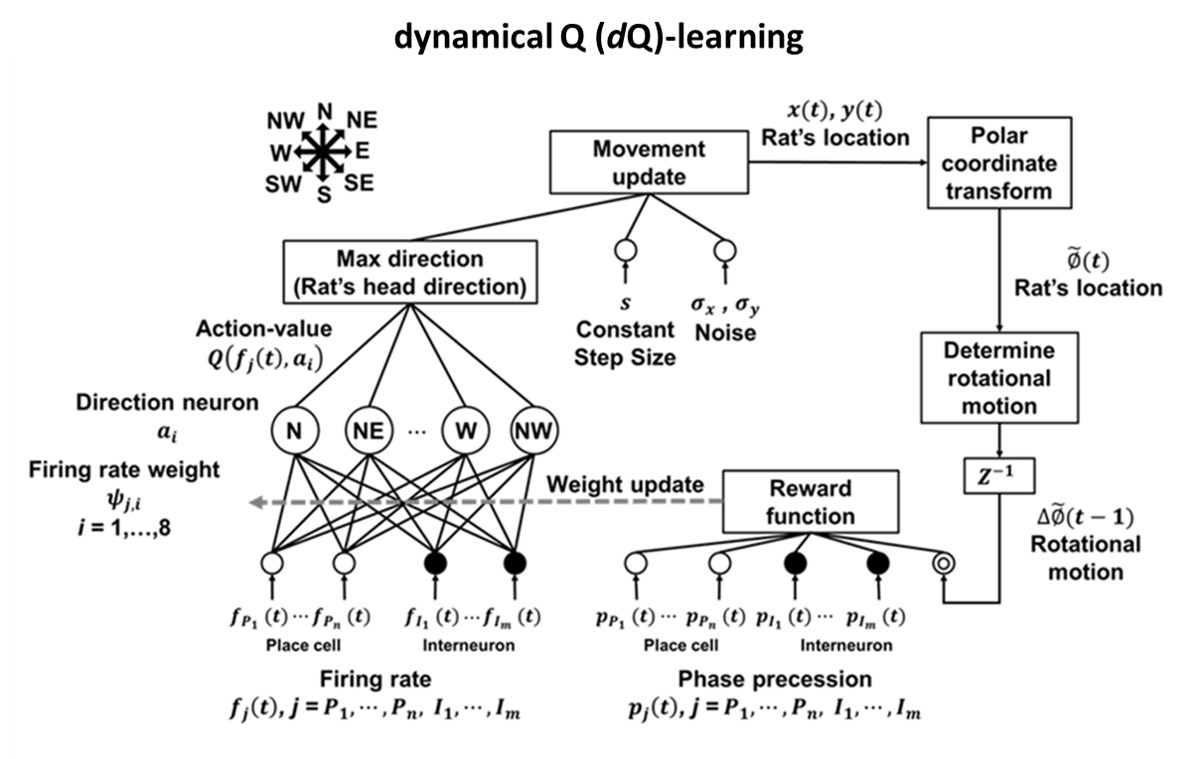
Fig3. The architecture of dynamical Q-learning
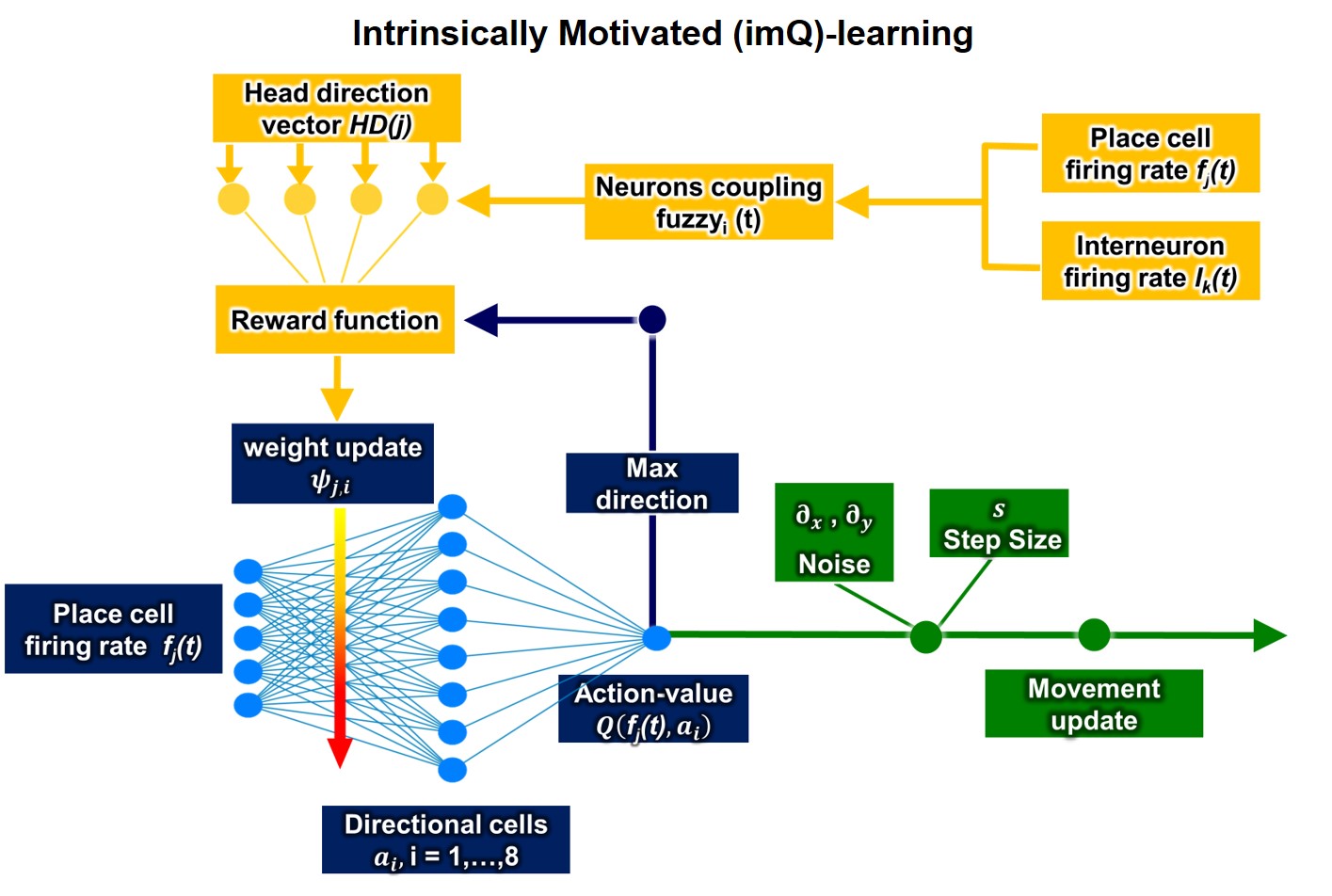
Fig4. The architecture of intrinsically motivated Q-learning
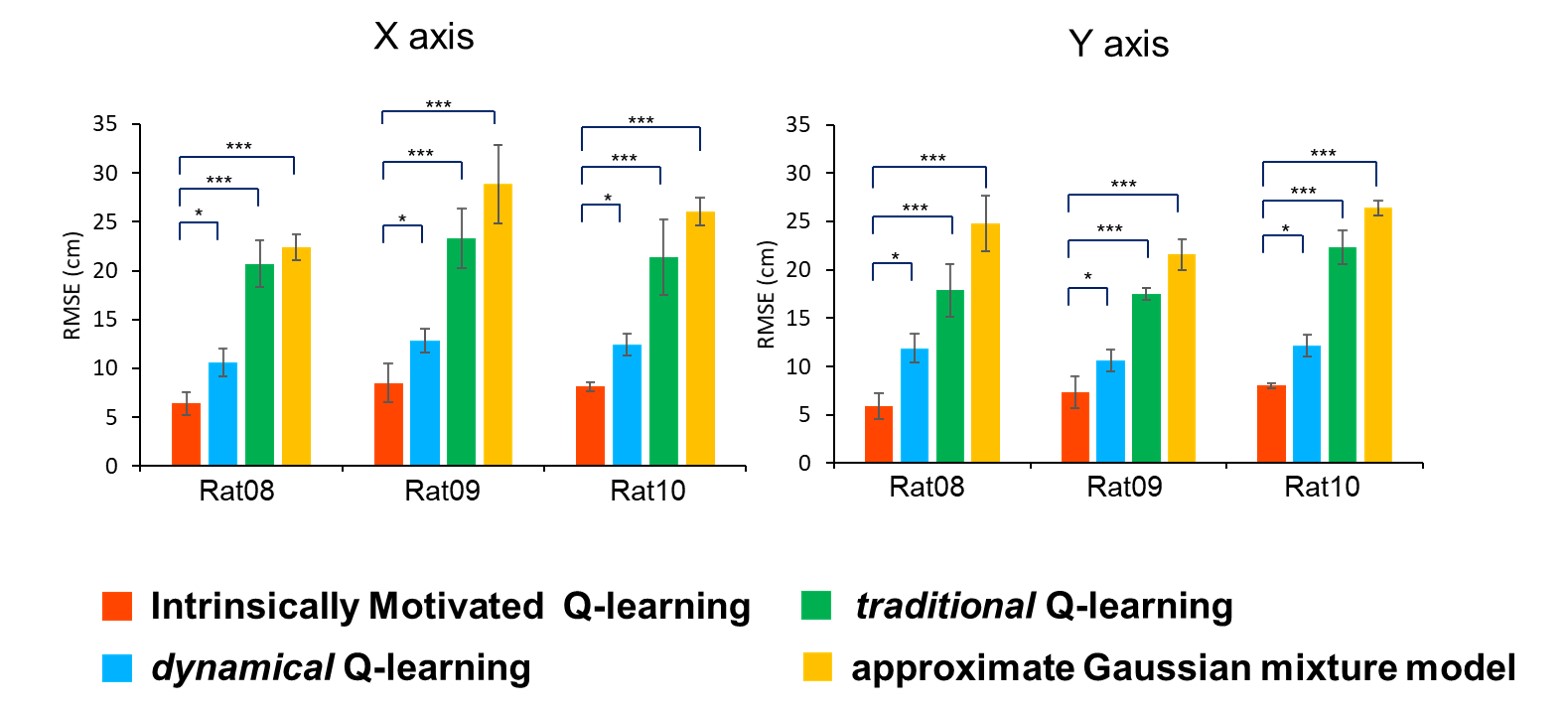
Fig5. The performance comparison of different navigation models. The data were based on RMSE between real trajectory and predected trajectory in X axis or Y axis.